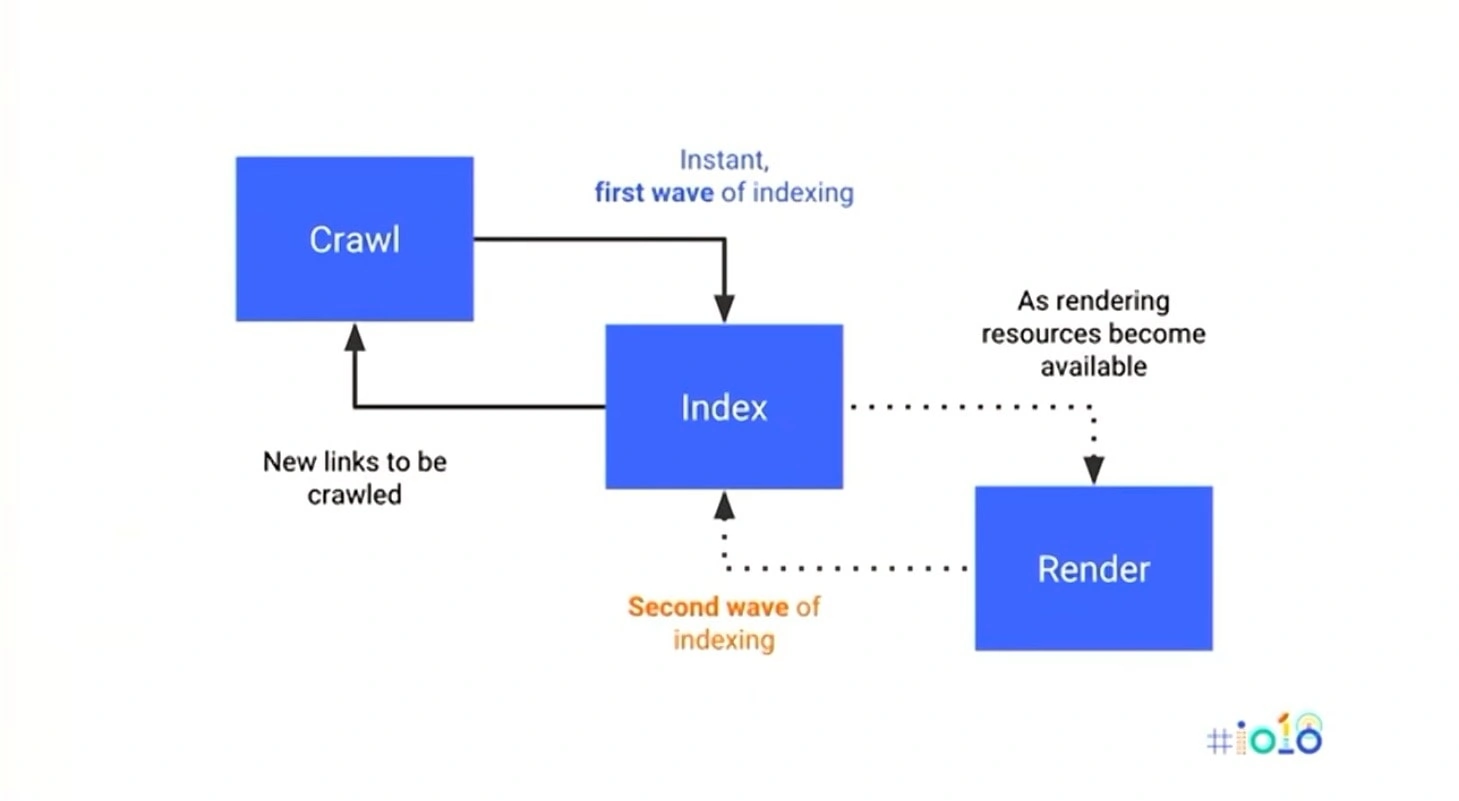
Google Indexe un site web en deux phases :
1) une indexation purement HTML
2) une indexation à l'aide un moteur de rendu (Chrome 41) qui permet de prendre en compte le Javascript.
Problème : la phase II n'est réalisée que lorsque des ressources sont disponibles dans les datacentres de Google. Dans la pratique; pluiseurs semaines peuvent s'écouler entre les deux phases.
Voir la vidéo :
https://youtu.be/PFwUbgvpdaQ
Source :
https://www.searchenginejournal.com/google-strongly-recommends-using-html-to-get-content-indexed-quickly/269841/
Continuer à lire "Google et site en JS"

Les générateurs de sites statiques sont apparus en 2008 (Jeckyll, Middleman). Ils permettent à partir d'un CMS, typiquement un logiciel de blog dynamique de type Wordpress, de générer des pages statiques. Cette approche permet de mettre en ligne un site très performant et offrant très peu de surface aux attaques. Il n'impose de plus que peu de contrainte à l'hébergeur.
Cet article liste quelques générateurs de sites statiques.
Sources :
Continuer à lire "Générateurs de sites web statiques"

Bien que souvent confondues, les notions de CMS headless et de CMS découplé sont distinctes. Cet article présente les principales caractéristiques de ce type d'architecture de manière théorique, c'est à dire indépendamment des outils réels existants sur le marché.
Dans un CMS classique comme Drupal, le backend (qui permet de composer les pages) et le frontend (qui affiche ces pages) sont inséparables.
Un CMS headless ne fournit que le backend et une API qui permet d'exposer le contenu saisi. La partie frontend (head) est absente.
Un CMS découplé est un CMS headless auquel est associé un frontend par défaut qui utilise l'API pour récupérer les contenus et les mettre en forme.
Sources :
-
https://www.coredna.com/blogs/headless-vs-decoupled-cms
-
https://www.contentful.com/blog/2019/02/04/difference-between-headless-decoupled-contentful/
Continuer à lire "Headless CMS - decoupled CMS - idées théoriques"
Lorsque, sous Windows, je fais appel à la barre de recherche Google, je tombe sur google.com avec une recherche paramétrée en anglais, c'est à dire qui va favoriser des sites en anglais... Je n'ai pas trouvé comment régler normalement ce problème. J'ai cependant une solution bricolée qui consiste à ajoute un moteur de recherche "Google Français" dans Firefox.
Il suffit de copier ce ficher
google-france.xml dans le répertoire des moteurs de recherche - par exemple dans
C:\Program Files\Mozilla Firefox\searchplugins, de relancer Firefox et de sélectionner dans la barre de recherche "Google-France" comme moteur et le tour est joué.
- Dictionnaire HunSpell en Français
- Lazarus: pour ne pas perdre les données saisies dans un formulaire en cas de plantage (serveur ou navigateur)
- QuickJava : activer / désactiver Java / Javascript rapidement
- Speed Dial : accès direct aux pages habituelles
- Firebug : un ensemble d'outil pour Webmestre
- Adblock Plus : suppression des pubs
- QuickPageZoom : ajoute des boutons pour zoomer / dézoomer
- Read it Later : éviter d'utiliser les bookmark pour un document à lire plus tard.
IDDN est un site web publié par InterDeposit, fédération internationale de l'informatique et des technologies de l'information, créée à Genève le 10 janvier 1994, et dont un des membre fondateur est l'
Agence de Protection des Programme.
Ce site permet de constituer une preuve de dépôt d'un fichier électronique utilisable en cas de conflits sur la propriété ou l'antériorité du fichier.
Continuer à lire "IDDN"
Le site
Blogopole présente une cartographie interactive des blogs politiques. La carte, signée
RTGI et
Exalead, répertorie plus de 2000 blogs et fait apparaître des pôles politiques en analysant les liens des sites les uns avec les autres. L'interface en Flash est assez réussie. Elle permet aussi par exemple grâce à un moteur de recherche intégré de voir l'impact d'un sujet dans chaque pôles.
Dans un
intéressant débat organisé par l'INA le 13 mars 2007,
Guilhem Fouetillou, co-fondateur de RTGI, a présenté cette initiative comme une vitrine pour la société RTGI, spécialisée dans la cartographie et l'analyse du NET par rapports à différents sujets.
Un documentation précise les partis pris et les conventions graphiques de la carte.
Continuer à lire "Cartographie de blogs politiques"
Pour partager des fichiers en utilisant Internet, on peut utiliser, par exemple :
-
WebDAV qui consiste à ajouter des fonctionnalités de modification de fichiers à un serveur Web. Le protocole a, par la suite, été complété par des fonctions de type contrôle de versions.
-
CIFS qui est en fait une modernisation (en tout cas marketing) du protocole SMB de Microsoft, bien connu des utilisateurs du logiciel libre
Samba.
-
WebNFS, moins connu, qui est une adaptation par Sun du protocole NFS.
Continuer à lire "Partage de fichiers via Internet"
Voici quelques documents utiles à qui recherche un éditeur HTML à insérer dans ses application Web :
-
La liste des principaux éditeurs très compète, elle contient à la fois des produits gratuits et commerciaux et reporte les compatibilités avec les principaux navigateurs (à vérifier tout de même).
-
Une comparaison des différents éditeurs open source qui date un peu (elle parle d'HTMLArea mais pas de Xinha).
-
Une évaluation qui porte aussi sur des éditeurs commerciaux.
Quelques ressources relatives à la diffusion de flux vidéo :
-
Une bonne introduction sur la diffusion en Streaming sur Internet.
-
Les différents formats de streaming avec les plateformes supportées et un introduction sur l'utilisation des encodeurs.
-
Comment encoder.
-
Une FAQ utile pour les personnes qui veulent diffuser un flux sur leur serveur web.
-
Empreinte propose une suite logiciel pour réaliser un streaming multi-format.
-
SMIL.
-
Freeware de manipulation de fichiers vidéos.
-
Vidéo à la demande sur Wikipedia.
-
La vidéo à la demande version Canal.
Derrière le concept fumeux, car recouvrant des réalités trop disparâtres, il y a un certains nombre de techniques intéressantes qu'il ne faudrait pas jeter avec l'eau du bain marketing.
Une chose est certaine : si le Web 1.0 séduisait par son économie de moyens (ex. HTML, push effectué avec des vrais protocoles push comme SMTP, le protocole de distribution des courriers électroniques,
REST), le web 2.0 brille souvent par sa non-préoccupation de l'optimisation (pages dynamiques, flux RSS, SOAP, ...)
-
Le dictionnaire du Web 2.0 par le Journal du Net, présente quelques techniques considérées comme faisant partie du Web 2.0.
-
L'article de Wikipedia est plus abscon.
Tous le outils pour interroger les serveurs de noms (association nom <-> adresse IP pour une machine connectée sur Internet) :
http://www.dnsstuff.com/
avec notamment un whois (identification du propriétaire d'un nom de domaine)
Dans une application web construite selon l'architecture
REST, l'URL (adresse web) est considéré comme une une URI (Uniform Resource Identifier) qui identifie une ressource (par exemple un compte client, une facture, une référence catalogue...). Dans ce contexte, idéalement, utiliser une application, c'est naviguer de ressource en ressource.
Par delà l'idéologie, cette approche présente un intérêt : elle rend tous les écrans de l'application "bookmarkables" (il peuvent être classés en tant que favoris). On n'est plus contraint de suivre un cheminement imposé par l'applicatif. On peut, au contraire, aller directement à un écran donné. NB : cela est possible dans la mesure où l'architecture REST est une architecture sans état.
Comment pratiquement arriver à un tel résultat ?
Continuer à lire "Redirections dans une application Web"






_still03.jpg)

